Based on Edge of Stochastic Stability (Andreyev and Beneventano, arXiv:2412.20553); correspondence to Pierfrancesco Beneventano, pierb@mit.edu.
Acknowledgements / lineage. I’m very grateful to Jeremy Cohen, Alex Damian, and Arseniy Andreyev for many discussions over the years that shaped how I think about stability-limited training and curvature. For an intuitive introduction to Edge of Stability, I especially recommend their writing at https://centralflows.github.io/.
Conceptual Map (where this is going): Inspired by the structure of those posts, I'll split this into three parts:
-
Part I (this post): a quick refresher on (full-batch) Edge of Stability (EOS) to set the scene for what comes next.
-
Part II: what changes for SGD, why “ hits ” is the wrong diagnostic, what diagnostics we came up with, and the Edge of Stochastic Stability (EoSS).
-
Part III: practical implications (hyperparameters, modeling SGD, and what this perspective changes).
Part I: A crash course on (full-batch) Edge of Stability
In this part I introduce the phenomenon and what I believe are the two key mechanisms—which we’ll use as the springboard for the mini-batch story of Part II.
Importantly, this part is not based on my work but on the work of Jeremy Cohen, Alex Damian and coauthors:
- Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability (Cohen et al., 2021)
- Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability (Damian et al., 2022)
1) Where does GD stop?
On a quadratic , , we can track it exactly: gradient descent (GD) with step size has the following update:
Thus exponentially fast… or maybe not.
The behavior is completely determined by the multiplier . When (equivalently ), the iterates converge to exponentially fast.
However, iterates could also diverge (for ) or oscillate in a period-2 orbit (for ), jumping between initialization and .
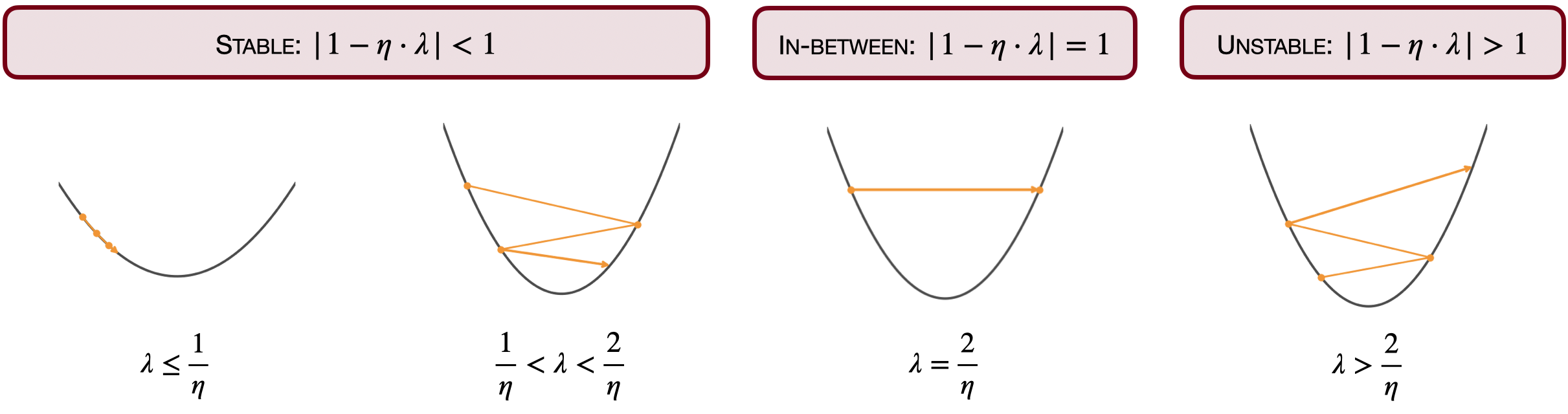
Classical optimization treats the latter two regimes as ‘wrong step sizes’. Surprisingly, modern neural nets often train successfully at this stability boundary—and that’s the story behind EOS.
2) Edge of Stability
Jeremy and co-authors (Cohen et al., 2021) made (at least) 2 sharp observations:
- As the loss goes down, sharpness (top-eigenvalue of the Hessian, our above) increases.
- When it reaches it stabilizes there; the loss keeps decreasing on average, but becomes non-monotone (oscillatory).
3) Mechanism 1: the instability threshold is when a power iteration happens
A major insight is that for self-stabilization to happen in full-batch algorithms, the algorithm needs to locally diverge, thus becomes unstable. Precisely, an EoS and AEoS is present when:
This is the mechanism of the oscillations we see in the train loss, and the main submechanism in the self-stabilization phenomenon above, the fact that as we enter the red—unstable—area, GD works as a power iteration along the direction of “high curvature”, precisely
4) Mechanism 2: Progressive Sharpening causes Self-stabilization
How is this possible, why is this the case unlike all the other optimization domains?
Arguably the only thing that changes and the only one that the gifs above are showing is that
What is called progressive sharpening: indeed, in observation 1 we saw that as the loss goes down the Hessian goes up!
And what about observation 2?
Alex, Eshaan, and Jason (Damian et al., 2022) showed that also that is a consequence of progressive sharpening!
To build up a mental picture of this, let’s pick the smaller landscape in which progressive sharpening is present: there are 2 variables, the gradient (going down inside the screen) points in a direction in which the Hessian grows (in the perpendicular direction).
We would expect here that the dynamics quickly reaches the river and flows towards sharper and sharper canyons, and this is what happens in the blue area (stable, ). By going down the dynamics enters the red area (unstable, ) and it diverges along the perpendicular direction (see GIF below).
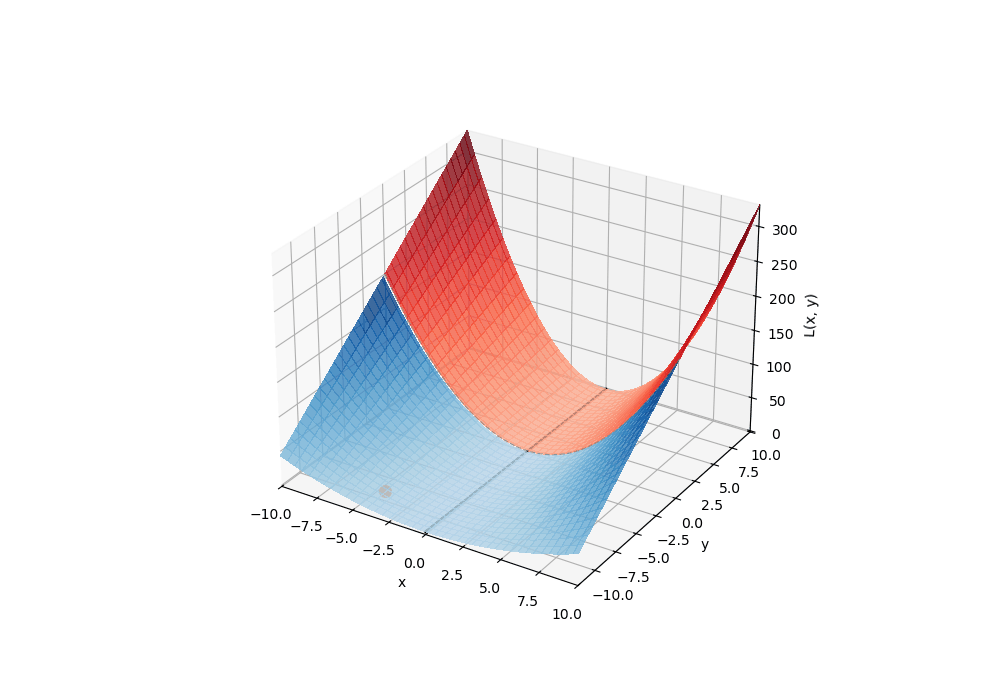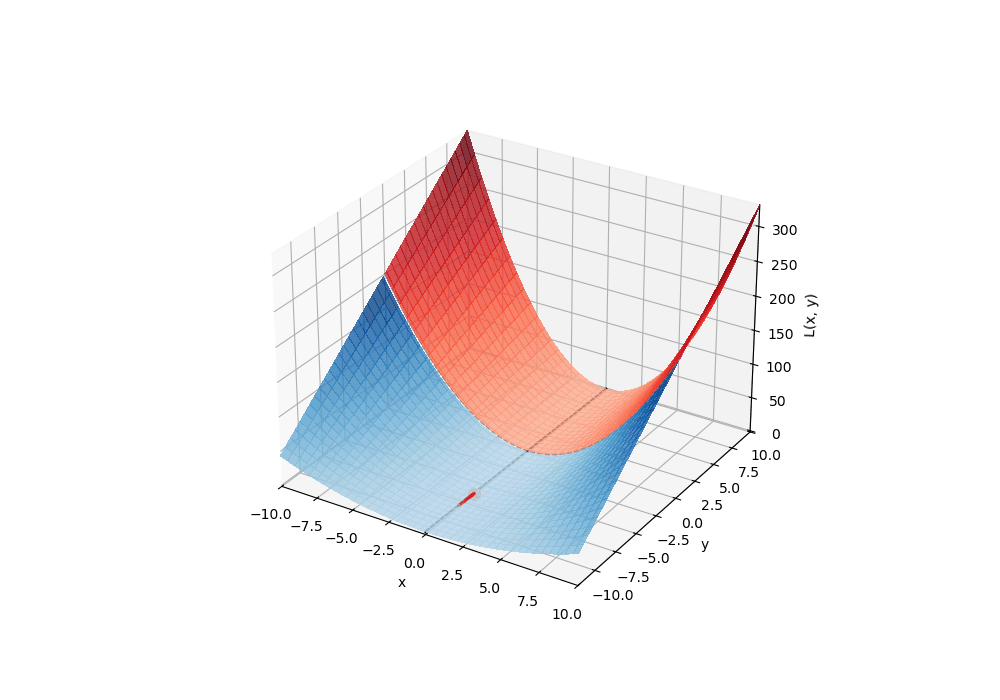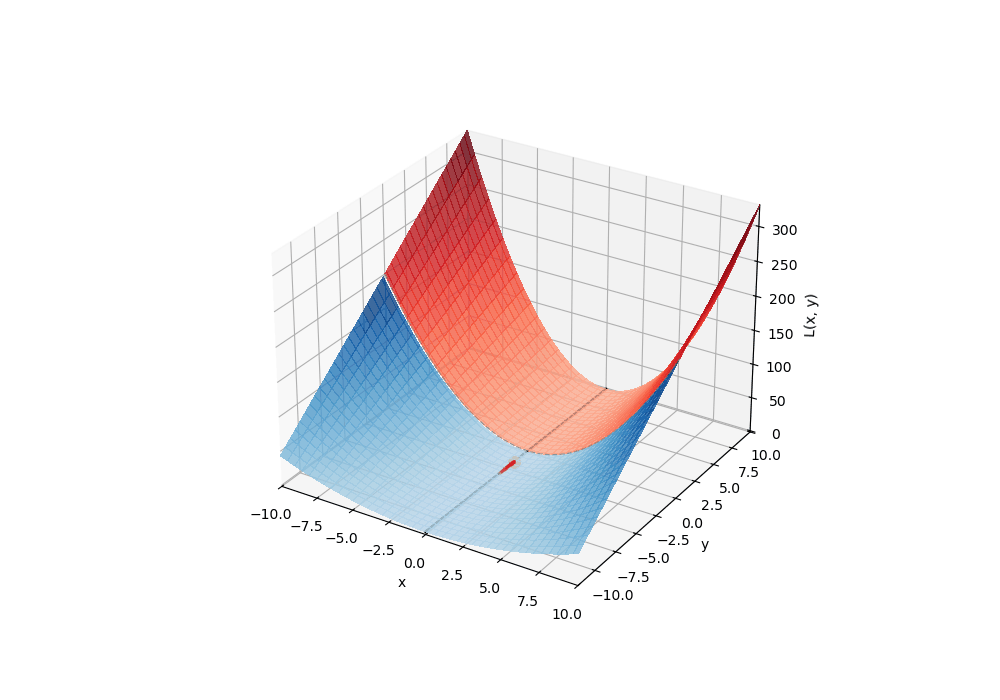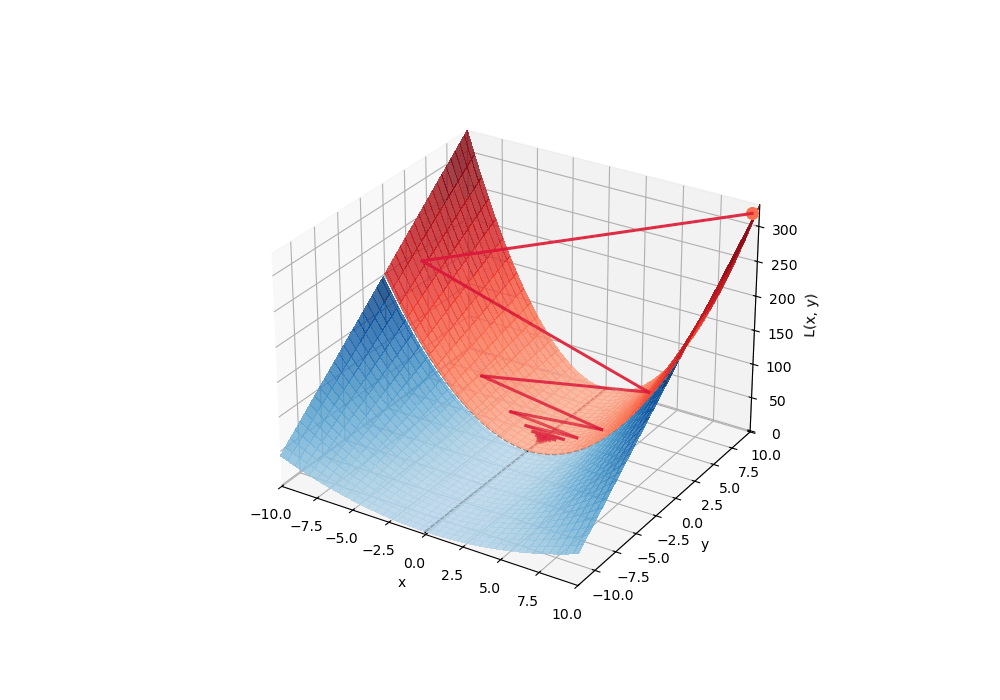
Actually... this is not the case and the gif above was straight made-up. The fact that it locally diverges implies that it goes in areas where the gradient points backward (because the gradient is perpendicular to the level lines and the level lines are curved, since going forward the landscape is sharpening!). Thus the trajectory jumps back in the blue area and the chaotic cycle restarts:
Gifs inspired by those on Alex Damian's website.
We thus saw that (1) progressive sharpening is not just an observation in early training—it is the observation that explains the whole phenomenon. The stabilization itself is caused by progressive sharpening.
In particular progressive sharpening is what causes Mechanism 2 (the self-stabilization phenomenon), when Mechanism 1 (the local divergence) kicks in.
So:
- We see oscillations in the loss because of this local instability (locally the loss is increasing).
- We see oscillations (self-stabilization) in the Hessian because of the third derivative pushing back.
5) Implications and Meaning
What we said so far implies that:
And with this also most arguments about location of convergence are broken, as long as most arguments that have been proposed by the community which hold under bounds on the Hessian.
Importantly, this is a further argument (the first in the literature being the proofs of implicit regularization) which shows a principle that mathematicians have to follow when working with neural network theory:
Cool, not only, this gives the first such argument supporting what practitioners always saw:
Moreover, Edge of Stability is a mechanism that surprisingly shows that:
6) Next what? Towards SOTA Optimizers (mini-batch)
All the results we saw so far hold for full-batch algorithms, precisely, GD, preconditioned/accelerated GD, full-batch RMSProp, full-batch Adam.
Neural networks are trained in a mini-batch fashion, do mini-batch algorithms behave differently?
Seemingly, they do behave differently as observed since Keskar et al. (2016), which was the observation that arguably started the research topic of “inductive bias of optimization algorithms” and that is the first paper, to my knowledge showing different hyper parameters go to qualitatively different minima. Precisely, they show, smaller mini-batches go to flatter minima (see our picture below)!
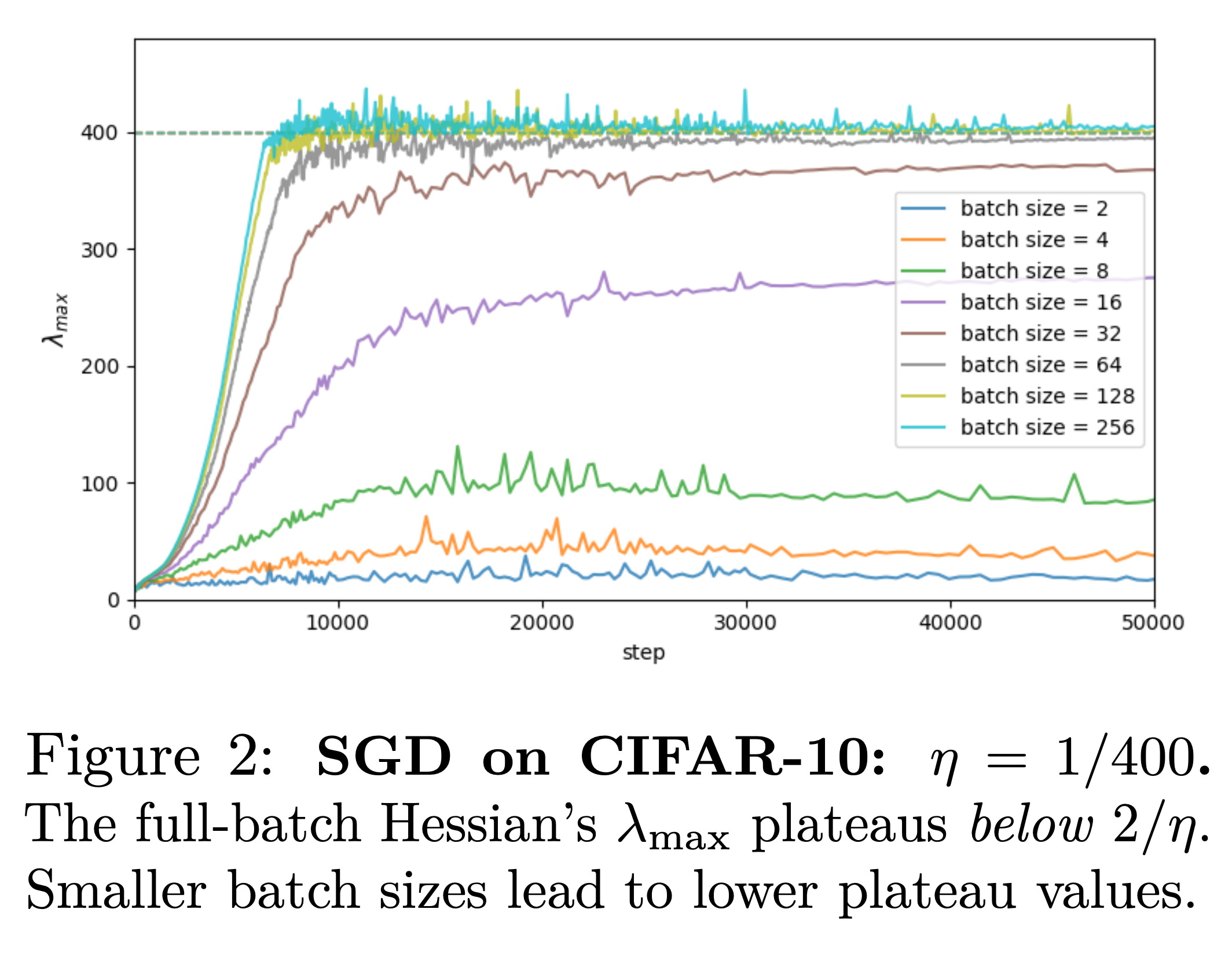
However, for instance, the loss of SGD always oscillates through the training, so do we care about oscillations or instability?
The punchline is, see Part II: for SGD, loss oscillations are not diagnostic, and of the full-batch Hessian typically does not track the relevant stability threshold—so we need a different, mini-batch-native notion of “edge.”
To bridge with the next parts, the questions here are:
How to find out whether other algorithms are working at their own version of EoS, what is that, and what are the implications? → Part II: The mini-batch case
Which implications carry and which new ones are there? Is this even interesting, apart the mathematical beauty of the description? → Part III: Getting practical